Yo también quiero usar el framework de ATT&CK
Si quieres mejorar las detecciones en tu SOC contra atacantes de tu organización, y además saber que posibles ataques priorizar, la última moda del momento es el framework ATT&CK y Threat informed defense.
Pero, si no tienes los recursos para contratar consultores externos para hacer el trabajo por ti, puede ser bastante abrumador para organizaciones pequeñas el subirse al tren de ATT&CK.
En una serie de entradas voy a intentar allanar el camino para ti, el único requisito es que conozcas tu organización, tu propia red, y que logs estas obteniendo ahora mismo. Con esa información disponible, voy a enseñarte como mapear a los TTPs de ATT&CK y encontrar los puntos ciegos en tu sistema de detección. Cuando terminemos con esta serie puedes tener un análisis de riesgos en condiciones basado en datos de atacantes, y esto solo con el conocimiento de tu red y unas geniales herramientas de código abierto. El único gasto va a ser en el café ☕ consumido mientras vamos haciendo el camino.
DeTT&CT
DeTT&CT es una herramienta de código abierto que nos ayudará con esta tarea, es muy útil y fácil de usar, aunque puede parecer bastante cuesta arriba al principio si no tienes experiencia en cómo ATT&CK funciona, pero aquí vamos a ver justo eso, sigue los pasos conmigo.
Me gustaría agradecer a Marcus Bakker (Twitter: @Bakk3rM) y Ruben Bouman (Twitter: @rubinatorz), autores de esta gran herramienta; gracias por ponerla disponible para beneficio de todos, y gracias por mantenerla actualizada con las nuevas versiones de ATT&CK. También tienen una muy buena documentación en su wiki por si quieres expandir en lo que voy a contar aquí.
Instalación
Puedes encontrar las instrucciones en la wiki, yo voy a hacer una instalación rápida con la imagen de docker en mi entorno Windows con WSL2. Si tienes un sistema Windows o Linux con Docker, puedes seguir estas instrucciones.
Crea dos directorios para los archivos generados por la herramienta - input y output.
mkdir input;mkdir output
Bajamos la imagen más reciente de docker:
docker pull rabobankcdc/dettect:latest
Ejecutamos el contenedor, mapeamos a un puerto en nuestro sistema anfitrión - por defecto la herramienta editor usa 8080, así que yo uso el mismo - y montamos los directorios input y output para guardar los archivos que crearemos más tarde.
docker run -p 8080:8080 -v $(pwd)/output:/opt/DeTTECT/output -v $(pwd)/input:/opt/DeTTECT/input --name dettect -it rabobankcdc/dettect:latest /bin/bash
Y ya está, ahora deberíamos estar dentro del contenedor y listos para empezar.
Data Sources
Como decíamos antes, empezar con ATT&CK, incluso con la ayuda de DeTT&CK, puede ser un poco abrumador, para vamos a hacerlo simple y directo. Lo primero que queremos saber es que podemos ver en nuestra red - asumo que ya tienes un infraestructura de recolección de logs funcionando. Pero para conocer nuestra visibilidad, primero tenemos que evaluar que datos estamos recogiendo.
Vamos a trabajar con las fuentes de datos tal como vienen definidas en el framework de ATT&CK, qe puedes consultar aquí. Actualmente hay 38 data sources, a su vez divididas en componentes de datos (data components), lo que hacen un total de 90 tipos de datos diferentes - como decía bastante apabullante cuando estamos empezando. Por suerte, en DeTT&CT tenemos todas estas fuentes predefinidas y listas para nosotros.
Iniciamos el edito de DeTT&CT desde dentro del contenedor:
python dettect.py e
Ahora abrimos el editor en nuestro navegador, bien en localhost o en la IP de la máquina virtual donde ejecutemos docker.
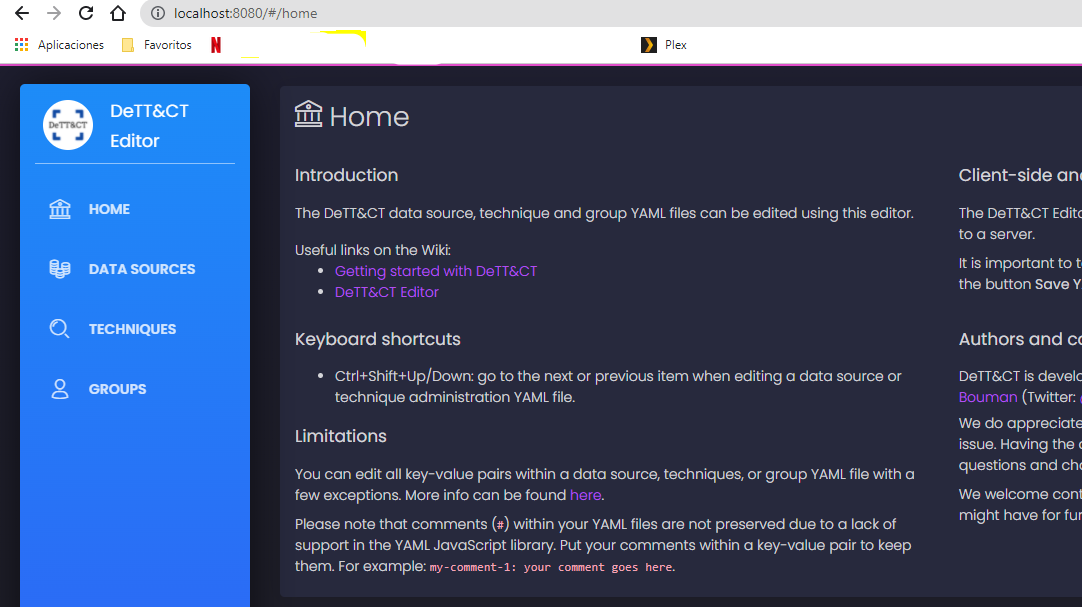
Hacemos click en Data Sources > New File y empezamos.
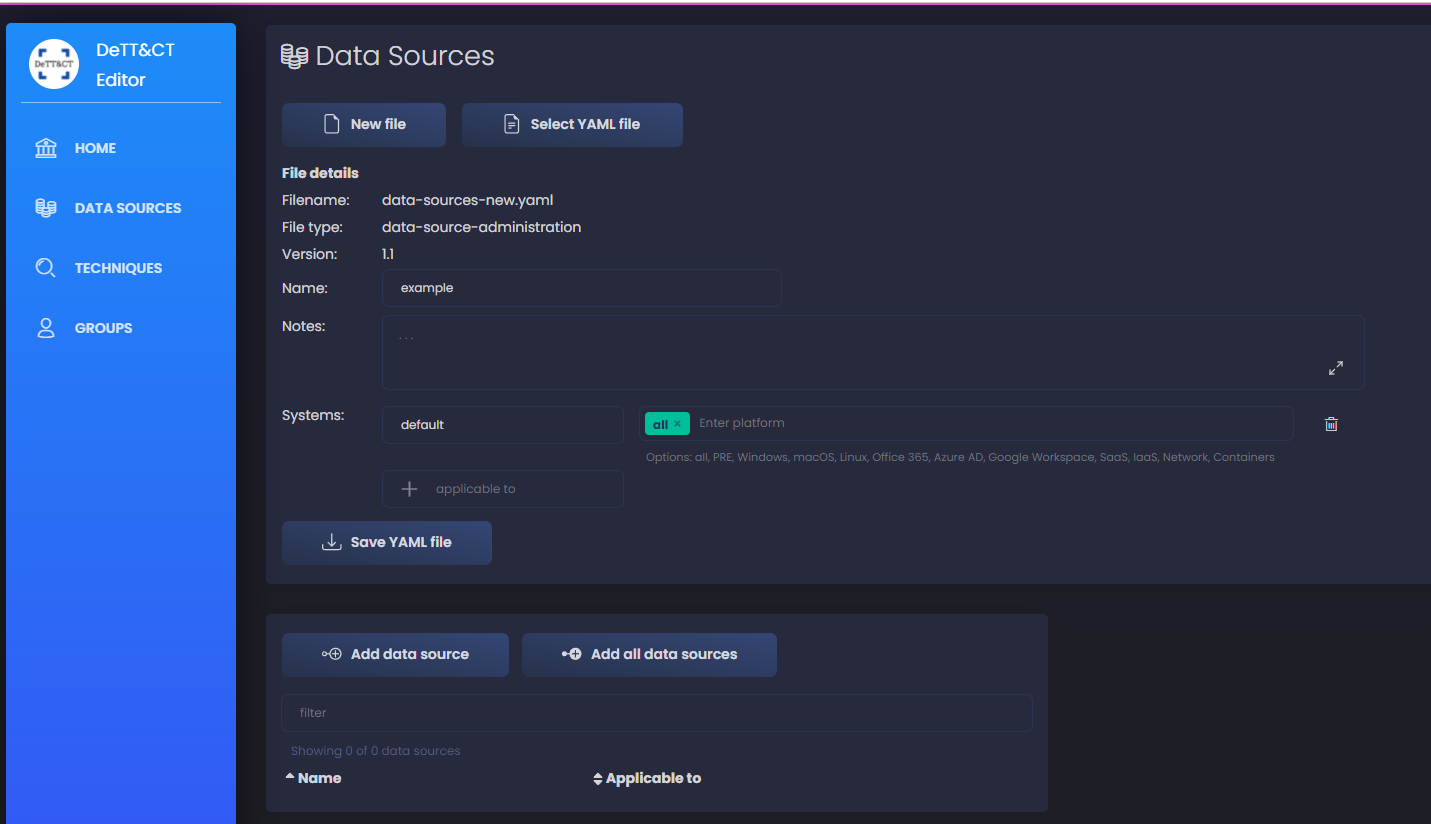
En un principio, voy a trabajar solo en la plataforma Windows, para hacerlo un poco más sencillo, pero una vez que le cojamos el truco, deberías hacer este proceso para todas las plataformas relevantes a tu red. También puedes usar diferentes sistemas para servidores y clientes para añadir granularidad - en el caso de que algunas fuentes de datos solo sean recogidas en servidores o viceversa. Podemos añadir más, como firewalls, routers o cualquier otro tipo de dispositivo en nuestra red.
Introduzco todos los datos del archivo como en la imagen:
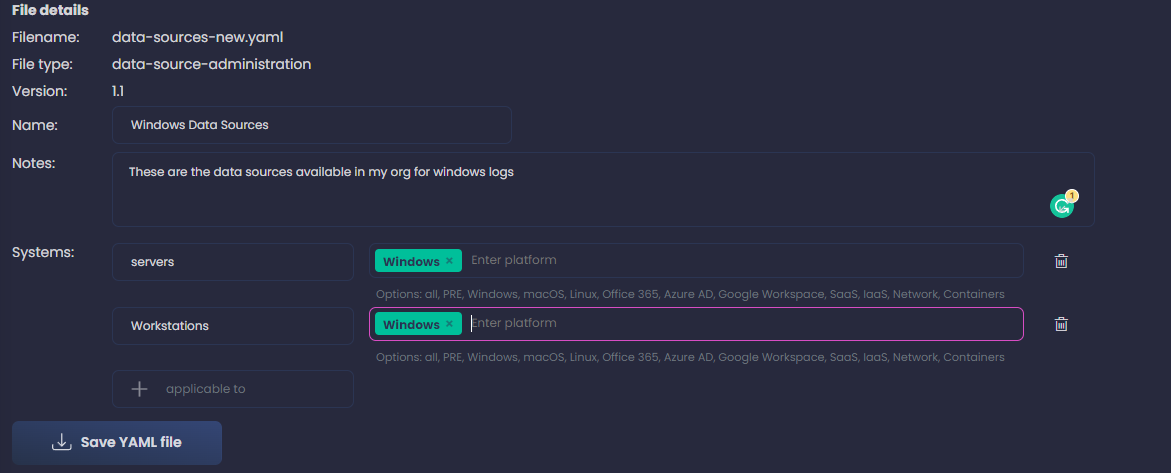
Recuerda, queremos incluir todas las fuentes de datos que estamos recolectando, no importa si tenemos alguna forma de detección implementada o no, simplemente el hecho de que tengamos los sistemas para recoger los logs es suficiente. Si además los almacenamos en algún lugar centralizado para su análisis posterior - normalmente un SIEM - lo marcaremos en los siguientes pasos para distinguirlo de los que no tenemos la posibilidad actualmente.
Usamos la página de data sources en MITRE como referencia, esto nos ayuda a ver si alguno de los logs que obtenemos incluye alguna fuente de datos en particular.

Ahora hacemos click a la izquierda en Add data source y una nueva ventana aparece a la derecha donde podemos empezar a añadir fuentes de datos.
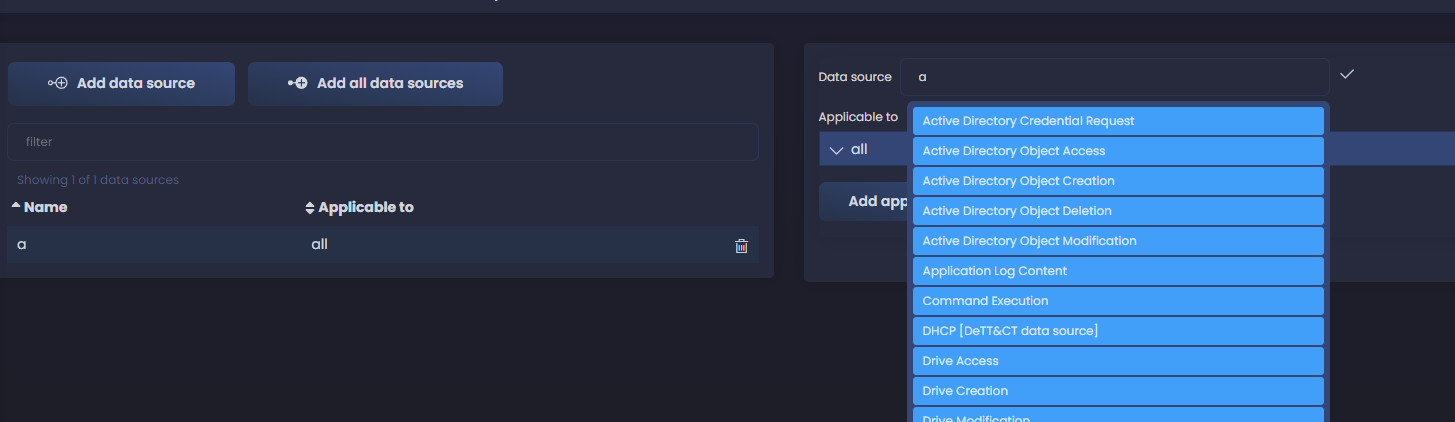
En cuanto empezamos a escribir, recibimos sugerencias de los data sources predefinidos. Si estamos recogiendo logs de Windows, podemos asumir que Active Directory es una de las fuentes de datos que consumimos, así que empecemos por una de ellas. Seleccionamos Active Directory Credential Request y empezamos a rellenar los campos.
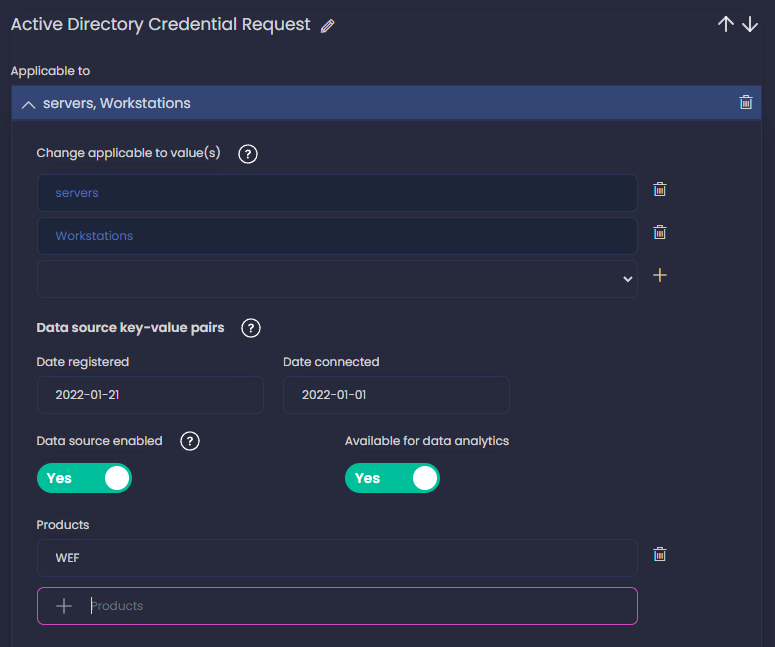
Hacemos click en Add applicable to y seleccionamos los sistemas donde sabemos que estamos recolectando logs para este data component. Selecciono los dos, servers y workstations - podemos también usar la palabra clave all si sabemos que se está consumiendo en todos nuestros sistemas; Añado hoy como la fecha en que he registrado el data component y también añado una fecha de cuando empecé a recolectar estos logs en mi red (en este ejemplo elijo una fecha cualquiera) - puedes dejar estos campos vacíos si no sabes cuando se empezó a consumir en tu organización.
A continuación, también habilito la fuente de datos - esto lo dejaríamos deshabilitado si por alguna razón no estamos obteniendo los logs en este momento, por algún problema puntual. También habilito Available for data analytics, esto significa que almacenamos los logs en un sitio accesible - un SIEM - para después procesarlos y usarlos para nuestras detecciones, no necesariamente que los estemos usando ya para detección, solo el hecho de que podemos.
También podemos añadir qué producto estamos usando para consumir la fuente de datos; en mi caso he añadido WEF. Puedes ver en la captura todos los valores configurados.
Ahora vamos a definir la calidad de los datos (Data Quality), un poco más abajo en la misma sección. Si hacemos click en icono de ayuda ❔ justo al lado de Data Quality, vemos el criterio para completar las 5 dimensiones que definen la calidad de nuestros logs.
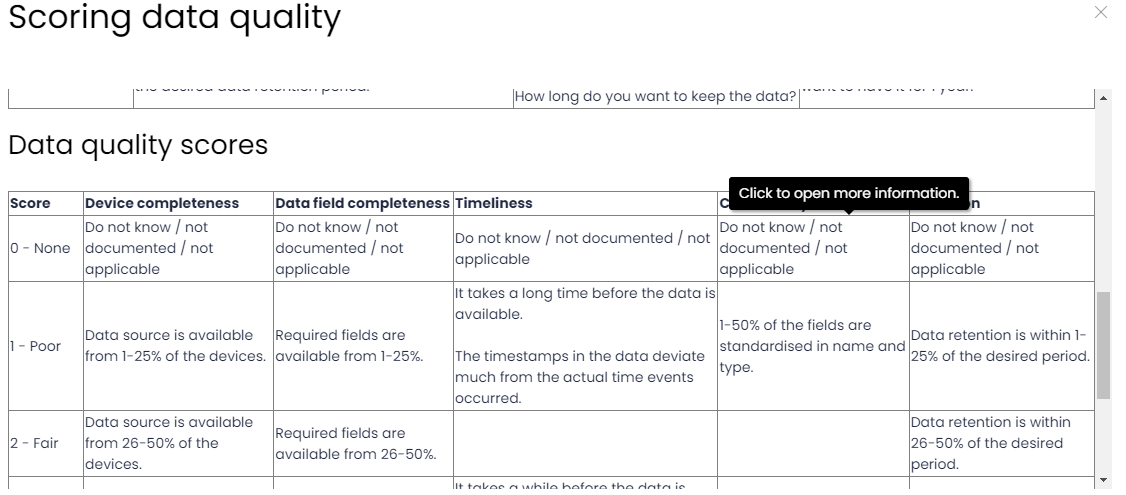
Como sugerencia, te digo que lo mejor es ser honesto y conservador cuando completes tus fuentes de datos, no queremos tener un falsa impresión de qué estás obteniendo que más tarde resulte en falsos negativos y no detecciones. También asegúrate de ser consistente durante todo el proceso, siempre usando el mismo criterio.

¡Y eso es todo, ya tenemos nuestra primera fuente de datos en nuestra configuración!
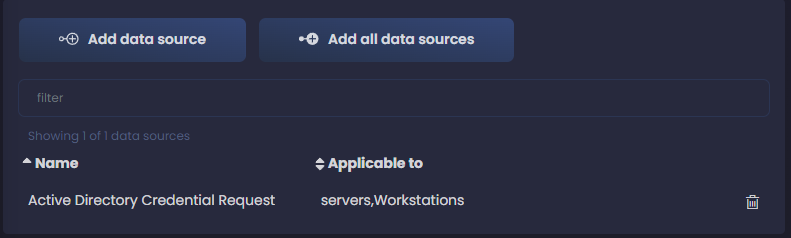
Volvemos a hacer click en Add data source y continuamos añadiendo todas nuestras fuentes de datos. Es un proceso tedioso en este momento, pero más tarde tendremos la recompensa, y creeme, merece la pena.
Metadatos al rescate
Completando esta tarea, si no estás seguro si estás almacenando alguna fuente de datos de la lista, o si no estás seguro si es relevante para tu entorno y deberías hacerte con ella, puedes ir a los metadatos de la fuente o componente para obtener más contexto. Por ejemplo, vamos a los detalles y metadatos de la fuente Cluster:
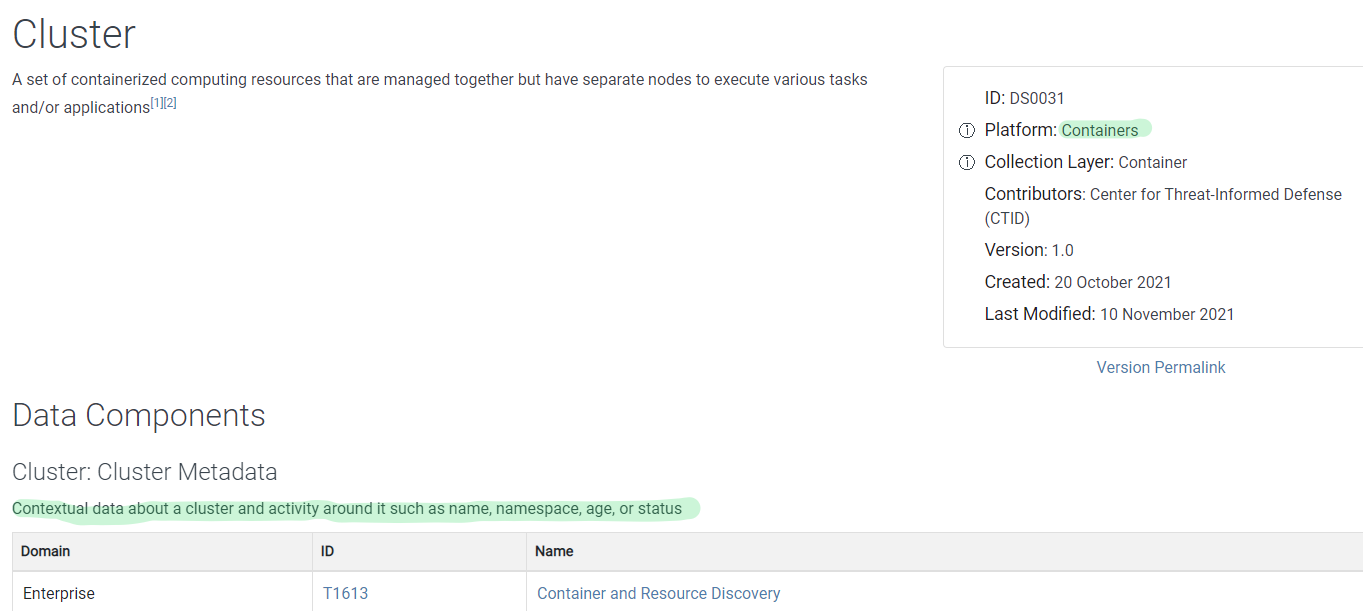
Podemos ver que solo afecta a contenedores, así que si no tenemos en nuestra red, no hay que preocuparse por ella.
Vamos a otro ejemplo, User Account, en los metadatos vemos las plataformas y capas de recolección; así vemos que es aplicable a las capas Windows y Host, las dos serían relevantes para mí. En los detalles de los componentes vemos qué ténicas y subténicas cada uno nos ayuda a detectar, y también ejemplos de logs con los que dicha fuente de datos puede ser obtenida - Windows EID 4625 o /var/log/auth.log para sistemas Linux.

ATT&CK Navigator
Una vez que tenemos todas las fuentes de datos cargadas en el editor, guardamos el archivo y ya podemos generar un archivo JSON para usarlo en el navigator de ATT&CK para mapear nuestras fuentes con los TTPs de framework.
Si quieres usar el archivo de fuentes que he creado para este ejemplo, puedes encontrarlo aquí; He simulado un sistema de auditado de Windows relativamente bien configurado, donde obtenemos logs relativos a Directorio Activo, grupos y cuentas de usuario. Esto no es perfecto ni mucho menos, de momento solo es una aproximación.
Fíjate que no he añadido las fuentes de datos de Registry y Process, esto ha sido intencionado, más adelante veremos por qué.
Ponemos el archivo YAML con las fuentes en el directorio input en nuestro sistema, para que sea accesible desde el contenedor de dettect.

Vamos al contenedor de dettect:
docker start -i dettect
Generamos el archivo JSON:
python dettect.py ds -fd ./input/data-sources-wef.yaml -l
Ahora podemos encontrar el archivo en el directorio output.

Ahora vamos a la aplicación navigator de ATT&CK aquí. Seleccionamos Open Existing Layer y el archivo JSON que acabamos de crear.
Esto abre la aplicación con nuestras fuentes de datos cargadas y mapeadas a todos los TTPs de ATT&CK a los que cubre. Puedes ver que tal como hemos configurado, solo es visible la plataforma windows.
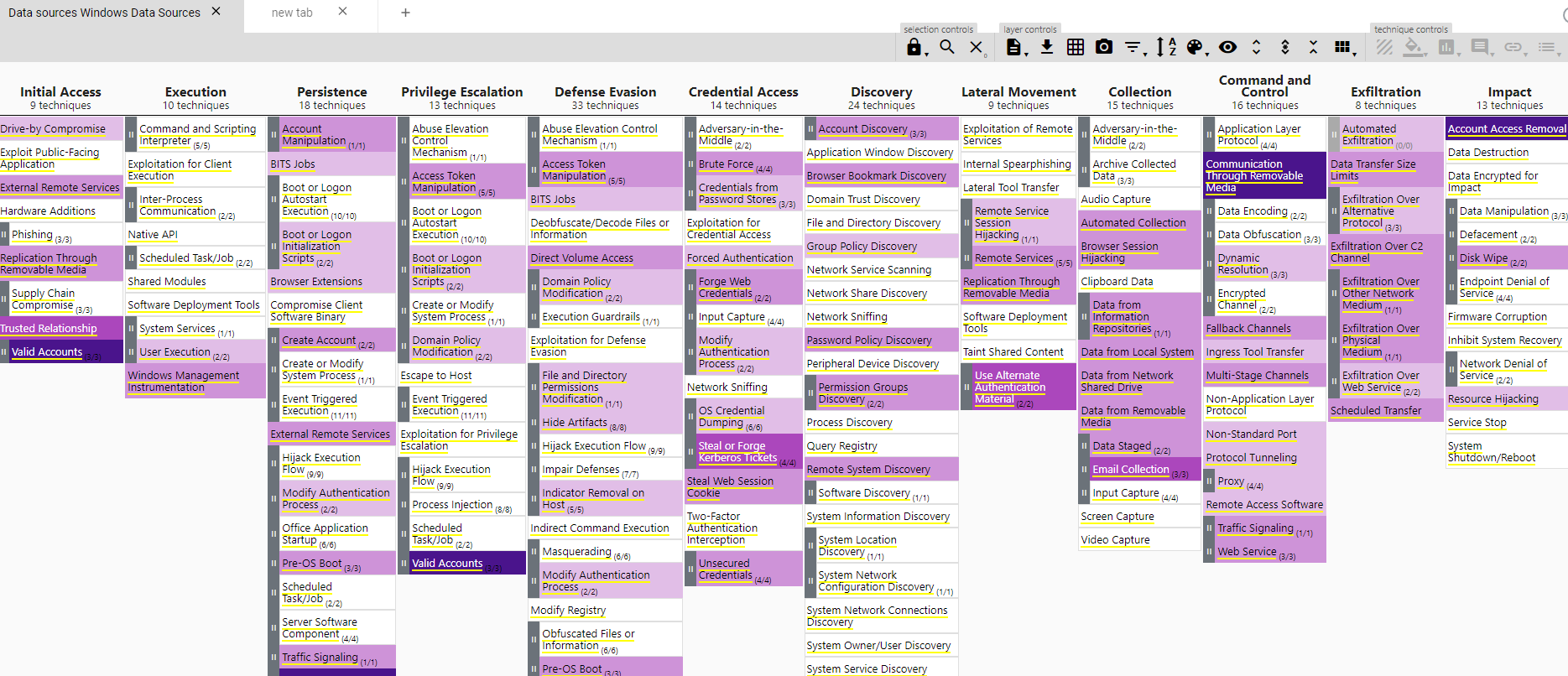
Después de todo el trabajo que hemos invertido en cargar nuestras fuentes de datos, ahora tenemos un muy buen mapa de la visibilidad que estas nos proporciona; podemos ya ver qué técnicas y subtécnicaas no estamos viendo con nuestras fuentes actuales. Ten en cuenta que esto es todavía una estimación de nuestra visibilidad, cuanto más oscura la tonalidad más fuentes tenemos cubriendo una determinada técnica y más posibilidades para su detección tenemos.
También podemos ver donde están las brechas en nuestra cobertura y que deberíamos empezar a priorizar. Digamos que queremos visibilidad en Command and Scripting Interpreter, que ahora mismo la tenemos en blanco, sin ninguna fuente de datos. Podemos pasar el cursor por encima y vemos que fuentes de datos nos darían visibilidad sobre ella. Con esto buscaríamos qué herramientas nos pueden conseguir esas fuentes en nuestro SIEM, como en este caso Sysmon.
Próximos pasos
Todavía nos faltan piezas en el puzle, podemos correlar estos datos con nuestros atacantes más probables por ejemplo. Este es solo el primer paso hacia nuestro análisis de riesgos. El próximo día, expandiremos nuestras fuentes de datos y obtendremos la visibilidad con un score por técnica y a ello añadiremos el mapeado de detecciones.
Verás que siguiendo este método, todas las piezas acaban cayendo en su sitio de manera natural y conseguimos una percepción mucho más precisa de nuestras amenazas y como afrontarlas.
¡Atento a la próxima entrada dentro de poco!